
Visualizing ChatGPT’s Performance in Human Exams
ChatGPT, a language model developed by OpenAI, has become incredibly popular over the past year due to its ability to generate human-like responses in a wide range of circumstances.
In fact, ChatGPT has become so competent, that students are now using it to help them with their homework. This has prompted several U.S. school districts to block devices from accessing the model while on their networks.
So, how smart is ChatGPT?
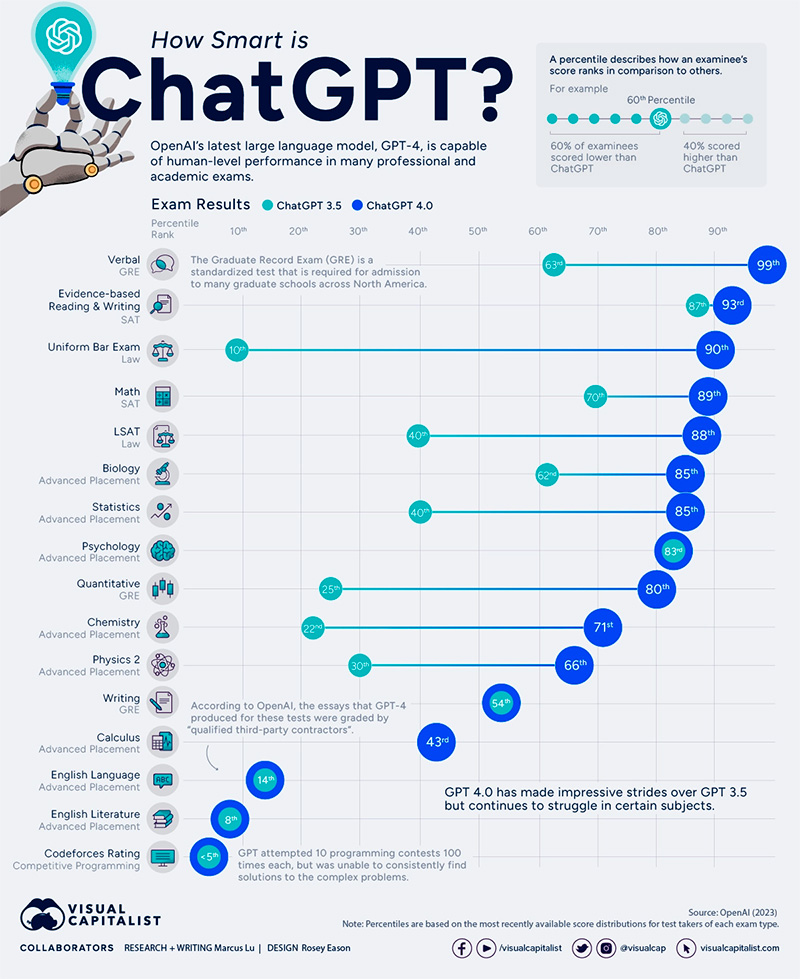
In a technical report released on March 27, 2023, OpenAI provided a comprehensive brief on its most recent model, known as GPT-4. Included in this report were a set of exam results, which we’ve visualized in the graphic above.
GPT-4 vs. GPT-3.5
To benchmark the capabilities of ChatGPT, OpenAI simulated test runs of various professional and academic exams. This includes SATs, the bar examination, and various advanced placement (AP) finals.
Performance was measured in percentiles, which were based on the most recently available score distributions for test takers of each exam type.
Percentile scoring is a way of ranking one’s performance relative to the performance of others. For instance, if you placed in the 60th percentile on a test, this means that you scored higher than 60% of test-takers.
The following table lists the results that we visualized in the graphic.
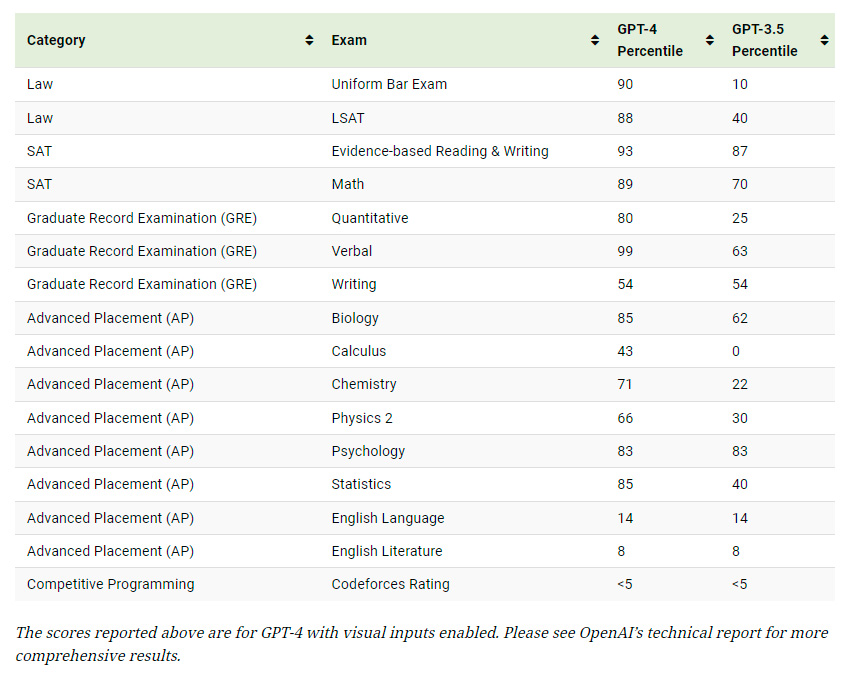
The scores reported above are for GPT-4 with visual inputs enabled. Please see OpenAI’s technical report for more comprehensive results.
As we can see, GPT-4 (released in March 2023) is much more capable than GPT-3.5 (released March 2022) in the majority of these exams. It was, however, unable to improve in AP English and in competitive programming.
Regarding AP English (and other exams where written responses were required), ChatGPT’s submissions were graded by “1-2 qualified third-party contractors with relevant work experience grading those essays”. While ChatGPT is certainly capable of producing adequate essays, it may have struggled to comprehend the exam’s prompts.
For competitive programming, GPT attempted 10 Codeforces contests 100 times each. Codeforces hosts competitive programming contests where participants must solve complex problems. GPT-4’s average Codeforces rating is 392 (below the 5th percentile), while its highest on a single contest was around 1,300. Referencing the Codeforces ratings page, the top-scoring user is jiangly from China with a rating of 3,841.
What’s Changed With GPT-4?
Here are some areas where GPT-4 has improved the user experience over GPT-3.5.
Internet Access and Plugins
A limiting factor with GPT-3.5 was that it didn’t have access to the internet and was only trained on data up to June 2021.
With GPT-4, users will have access to various plugins that empower ChatGPT to access the internet, provide more up to date responses, and complete a wider range of tasks. This includes third-party plugins from services such as Expedia which will enable ChatGPT to book an entire vacation for you.
Visual Inputs
While GPT-3.5 could only accept text inputs, GPT-4 has the ability to also analyze images. Users will be able to ask ChatGPT to describe a photo, analyze a chart, or even explain a meme.
Greater Context Length
Lastly, GPT-4 is able to handle much larger amounts of text and keep conversations going for longer. For reference, GPT-3.5 had a max request value of 4,096 tokens, which is equivalent to roughly 3,000 words. GPT-4 has two variants, one with 8,192 tokens (6,000 words) and another with 32,768 tokens (24,000 words).




